
узнайте, чем мы можем помочь вашей компании
Оставьте заявку, чтобы мы вас проконсультировали по нашим услугам
закажите проект
для своей компании
для своей компании
Оставьте заявку, и мы расскажем, как можем автоматизировать бизнес-процессы
заказать разработку чат-бота
Оставьте заявку, чтобы мы вас проконсультировали по созданию чат-бота


редомендаций
для youtravel
система

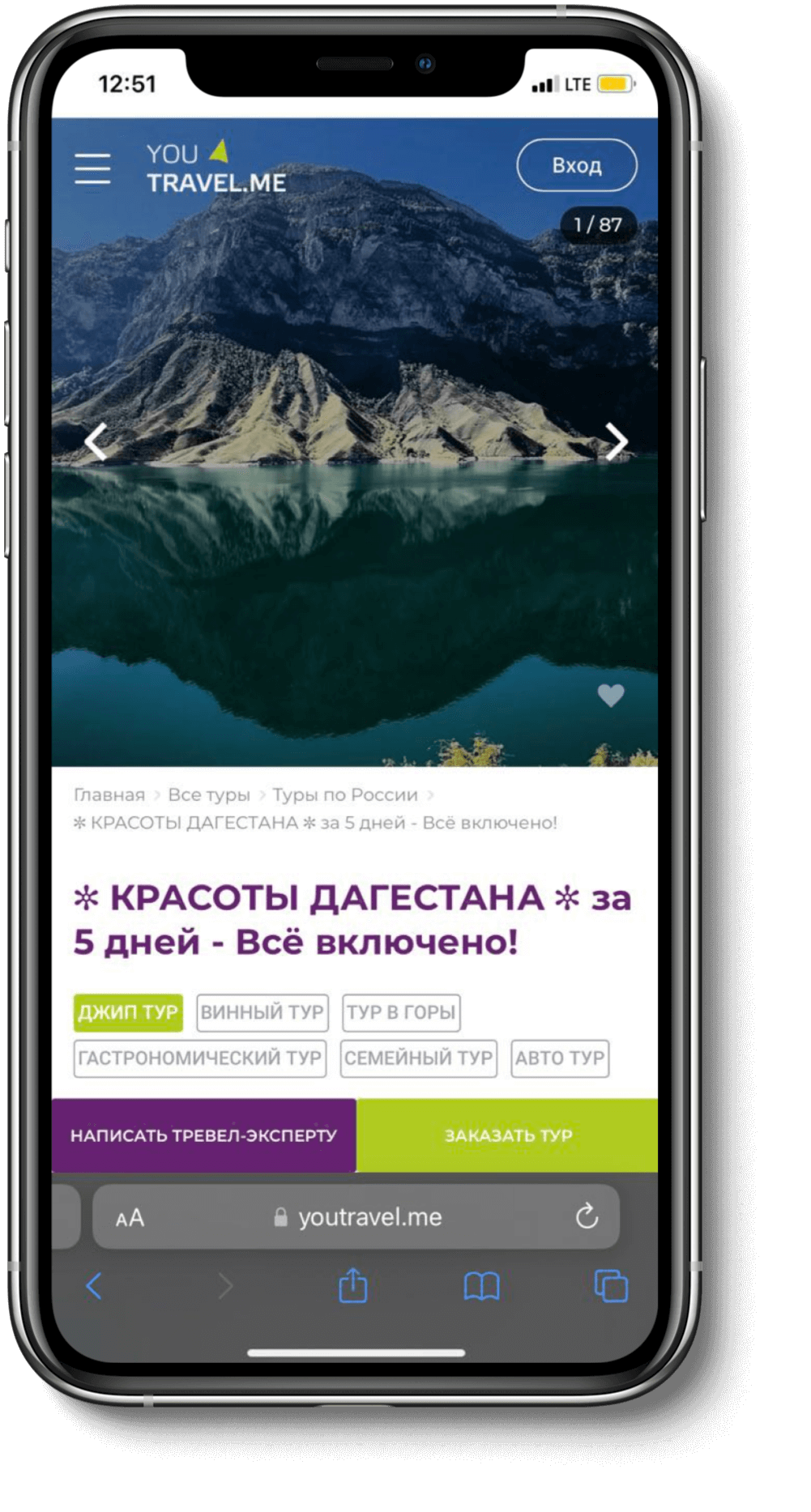
YouTravel.me — маркетплейс авторских туров от тревел-экспертов и частных независимых гидов. На сайте почти 40 000 предложений. Тут можно быстро и безопасно найти тур и отправиться в необычное путешествие в любую точку мира.
Разработали для крупного маркетплейса продвинутую персонализацию, основанную на ML-модели.
Пользователь не видит весь объем предложений под свой запрос, не находит нужного и уходит. Бизнес теряет деньги.
Сегодня персонализация в ecommerce — это в основном блоки «Вам понравится также», «С этим товаром покупают» или upsell-рекомендации в корзине. Интеграция в эти места самая дешевая и несложная, но эффективность у таких решений крайне низкая.


ПРОБЛЕМА
Задача
Разработать систему рекомендаций, которая будет встраиваться во все листинги на сайте и учитывать максимум пользовательских интересов.
Такую продвинутую персонализацию мы будем создавать на основе машинного обучения и анализа данных. Именно на этих направлениях специализируется наше подразделение AGIMA AI.
Такую продвинутую персонализацию мы будем создавать на основе машинного обучения и анализа данных. Именно на этих направлениях специализируется наше подразделение AGIMA AI.
Решение
Мы придумали стратегию персонализации, которая позволяет интегрироваться на уровне пересортировки любого листинга, у которого уже есть своя логика формирования. Мы не просто отдаем список рекомендованных объектов по API, мы реализуем:
- сбор ленивых просмотров и большого количества поведенческой информации;
- метод пересортировки любого списка товаров под каждого отдельного клиента.


Чтобы персонализация работала, нужен сбор данных про пользователя.
Совместно с YouTravel мы сделали систему по сбору информации о том:
Совместно с YouTravel мы сделали систему по сбору информации о том:
- что пользователь видел на странице,
- на что кликнул,
- куда перешел.
СБОР ДАННЫХ
Казалось бы, можно просто извлечь категорию из текстового названия, но нет. Если в каталоге Ozon появятся новые категории, придётся обучать модель заново. Этот процесс дорогой и довольно хрупкий — в любой момент могут возникнуть ошибки по всему пространству данных и риск неверно классифицировать товары. Наш подход позволяет этого избежать
Деление товаров на категории и типы происходит на основе похожих объектов. С помощью машинного обучения мы находим группу товаров, наиболее близкую по характеристикам (или числовым значениям, если мыслить в терминах Ozon). К их категории подходит и наш товар

«Ключевой момент в нашем сборе данных — это учет ленивых просмотров. В типичном трекинге сбор информации про просмотры без взаимодействия отсутствует. А нам важно знать, что пользователь видел вот эти 20 товаров, но ничего не выбрал и не совершил никакого действия. Эта информация необходима для статистики и для обучения ML-модели».
генеральный директор AGIMA AI
Андрей Татаринов
Как всё устроено
Нужно сделать схему размещения, на картинках прописаны заголовки для карточек в схемах


О покупках.
О ленивых просмотрах.
Мы доработали систему сбора данных (и со стороны заказчика, и с нашей) таким образом, чтобы получать информацию:


О глубоких просмотрах (просмотры карточки товара).
Мы получаем данные с фронтенда и кладем в два места:
Сюда в реальном времени поступает поток событий с фронтенда и поддерживается реалтайм-представление о том, что мы знаем про пользователя.
- Долгосрочное хранилище — для переобучения модели подсчета статистики.
- Онлайн-профиль — в моменте отвечает на вопрос, какие предпочтения у пользователя, какое поведение он проявил только что.
Сюда в реальном времени поступает поток событий с фронтенда и поддерживается реалтайм-представление о том, что мы знаем про пользователя.
Процессинг данных
Мы получаем данные с фронтенда и кладем в два места:
Сюда в реальном времени поступает поток событий с фронтенда и поддерживается реалтайм-представление о том, что мы знаем про пользователя.
- Долгосрочное хранилище — для переобучения модели подсчета статистики.
- Онлайн-профиль — в моменте отвечает на вопрос, какие предпочтения у пользователя, какое поведение он проявил только что.
Сюда в реальном времени поступает поток событий с фронтенда и поддерживается реалтайм-представление о том, что мы знаем про пользователя.

В это время наша API рекомендаций на основе ML-модели реализует самый главный метод — метод пересортировки списка товаров.
API забирает информацию из онлайн-профиля, чтобы узнать, какими свойствами обладает пользователь, для которого мы делаем пересортировку, и держит в памяти модель персонализации.
API забирает информацию из онлайн-профиля, чтобы узнать, какими свойствами обладает пользователь, для которого мы делаем пересортировку, и держит в памяти модель персонализации.
Это онлайн-цикл работы, он происходит за полсекунды в процессе работы сайта с пользователем.
Есть еще длинный цикл взаимодействия — ежечасно мы забираем статистику, которая накопилась, пересчитываем матрицы рекомендаций и принудительно обновляем модель в API. Примерно раз в час предрасчитанные рекомендации по каждому отдельному пользователю обновляются.
Полное решение выглядит так:
Есть еще длинный цикл взаимодействия — ежечасно мы забираем статистику, которая накопилась, пересчитываем матрицы рекомендаций и принудительно обновляем модель в API. Примерно раз в час предрасчитанные рекомендации по каждому отдельному пользователю обновляются.
Полное решение выглядит так:


У нас есть три стратегии, в рамках которых мы делаем рекомендации для пользователя. Все три работают одновременно.
Стратегии рекомендаций
Вся информация о товаре разбивается на свойства (например, «материал») и значения («искусственная кожа»). Проблема в том, что у продавца и у Ozon они могут называться по-разному (не «искусственная кожа», а «кожзам»).
Наша задача в рамках машинного обучения — понять, что это одно и то же. Для этого система анализирует свойства и значения в числовом формате и мэтчит их с параметрами Ozon. В результате мы из сырых данных получаем табличку с необходимым для публикации контентом
Пользователь находится на сайте больше 30 минут. Он уже попал в ежечасный цикл переобучения. Поэтому мы пользуемся хорошо рассчитанным вектором свойств пользователя и делаем рекомендации. Они получаются самыми качественными.
Холодный пользователь. Он только что пришел, мы о нем ничего не знаем, но нам надо ему что-то порекомендовать. В этом случае мы используем статические фичи, которые выражаются не в его поведении, а в его свойствах (какой язык на сайте выбран, из какого региона, с какого устройства и т. п.).
Пользователь пришел недавно. Его еще нет в рассчитанных фичах, но он уже успел проявить свое поведение, например, кликнул на один товар. В этом случае мы делаем хорошее предположение относительно его предпочтений на основании свойств товара, к которому он проявил интерес, и формируем для него рекомендации.
Вот так выглядит конверсия в клик в разрезе по стратегиям:

unknown by history применяется для пользователей, которые находились на сайте больше 30 минут и успели проявить свое поведение; для них система показывает лучшие результаты.
Что получилось в результате
Сейчас наша стратегия интегрирована в часть листингов на сайте YouTravel, результаты такие:
Если средняя конверсия из показа в клик без рекомендаций — от 3% до 4,5%.
То у персонализированных предложений — от 6% до 9%.
За два месяца мы смогли добиться двукратного увеличения целевого действия. И это не предел!
Если средняя конверсия из показа в клик без рекомендаций — от 3% до 4,5%.
То у персонализированных предложений — от 6% до 9%.
За два месяца мы смогли добиться двукратного увеличения целевого действия. И это не предел!
Без машинного обучения конверсия из визита на сайт в клик по туру составляет около 3%. С машинным обучением конверсия в клик может достигать 9%.

Это не конец, а только начало

Мы продолжаем работу над проектом.
Т.к. большая часть показов приходится на долю холодных пользователей, активно улучшаем холодные рекомендации — включаем больше статической информации в рекомендации.
Например, пробуем учитывать рекламную кампанию, по которой пришел пользователь, учимся понимать текст объявления и забирать это в рекомендации.
Помимо этого, учитываем:
Т.к. большая часть показов приходится на долю холодных пользователей, активно улучшаем холодные рекомендации — включаем больше статической информации в рекомендации.
Например, пробуем учитывать рекламную кампанию, по которой пришел пользователь, учимся понимать текст объявления и забирать это в рекомендации.
Помимо этого, учитываем:
лендинг, на котором пользователь приземлился;
модель телефона, с которого он зашел;
язык сайта/браузера, который определился для пользователя;
его географию.
Используемые технологии
REST/GRPC
Kafka/PG/HTTP push
Prometheus Grafana
Python/FastAPI
GPU
Python Airflow/Prefect
Redis
MLflow/S3/HDFS/Hive
Pytorch/XGB
Metabase/Superset/Tableau
Jupiter
над проектом работали
YouTravel
- Технический директор
- Product-менеджер
AGIMA AI
- ML-разработчик
- Backend-разработчик
- Аналитики
контакты AGIMA AI
hello@agima.ai
107031, г. Москва, ул. Петровка, д. 19, стр. 4.

Теперь вы знаете, где нас искать
Обычно мы работаем с 10 до 19.
Обычно мы работаем с 10 до 19.

станьте клиентом AGIMA AI
Оставьте заявку, чтобы начать сотрудничество