
узнайте, чем мы можем помочь вашей компании
Оставьте заявку, чтобы мы вас проконсультировали по нашим услугам
закажите проект
для своей компании
для своей компании
Оставьте заявку, и мы расскажем, как можем автоматизировать бизнес-процессы


для определения
товаров на видео
Проектирование и обучение AI
Разработка ML-модели
Задача


Разработать Shazam для видео. Научить приложение определять название и выдавать список товаров из видео.
Например, по телевизору идет фильм «Мистер и миссис Смит». Пользователь открывает приложение и наводит камеру на экран. Система показывает название фильма и список товаров: одежду главных героев, аксессуары, марки автомобилей и многое другое, — все, что загрузит в базу правообладатель.
Нужно сделать схему размещения, на картинках прописаны заголовки для карточек в схемах

Распознавание монитора
Первая задача — научить приложение определять, что перед ней монитор. Для этого мы собрали и разметили изображения, на которых видны включенные мониторы.
Первая задача — научить приложение определять, что перед ней монитор. Для этого мы собрали и разметили изображения, на которых видны включенные мониторы.
Превращение кадра в числовый вектор — эмбеддинг
Обучили эмбедер, который представляет информацию на кадре в виде числового вектора. Похожие кадры лежат близко друг к другу в векторном пространстве, а разные кадры — далеко.
Обучили эмбедер, который представляет информацию на кадре в виде числового вектора. Похожие кадры лежат близко друг к другу в векторном пространстве, а разные кадры — далеко.
Работа с базой
Чтобы найти тот самый фильм, который снимает пользователь, нам нужна база фильмов. Мы взяли 150 видео, разбили их на кадры и оцифровали каждый кадр с помощью эмбедера. Кадры-векторы загрузили в базу Milvus, которая позволяет быстро искать похожие векторы.
Чтобы найти тот самый фильм, который снимает пользователь, нам нужна база фильмов. Мы взяли 150 видео, разбили их на кадры и оцифровали каждый кадр с помощью эмбедера. Кадры-векторы загрузили в базу Milvus, которая позволяет быстро искать похожие векторы.
Создание списка товаров
Создали и заполнили облачную базу данных со всей информацией о каждом видео, сегментах видео и товарах, которые встречаются в них.
Создали и заполнили облачную базу данных со всей информацией о каждом видео, сегментах видео и товарах, которые встречаются в них.



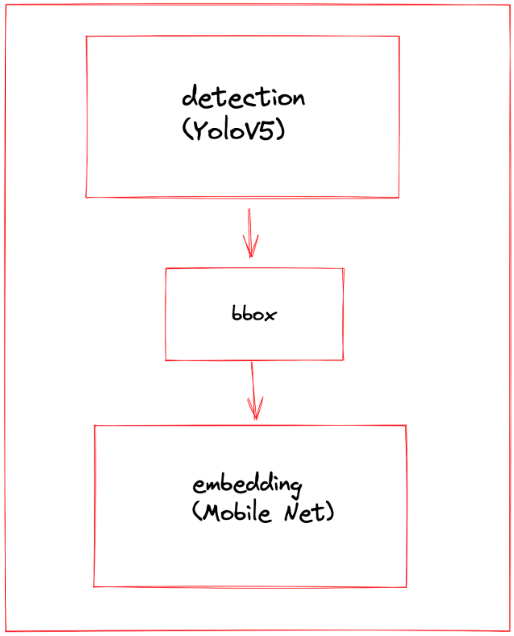
Этапы разработки
Этот проект ункален с точки зрения машинного обучения. Здесь было важно сделать не только решение с высоким качеством распознавания, но и оптимизировать его для исполнения в реальном времени на мобильном устройстве. Вместе с командой Amiga мы портировали пайплайн распознавания на Dart и получили решение, которое отлично работает в реальном времени на широком спектре мобильных устройств и на iOS, и на Android.
генеральный директор AGIMA AI
Андрей Татаринов

Приложение сравнивает кадры, снятые пользователем, с кадрами из базы Milvus. Базу мы заранее заполнили раскадровками 150 фильмов и присвоили каждому из них числовой вектор.
Числовые векторы-кадры из видео пользователя сопоставляются с векторами-кадрами из базы Milvus. Посредством голосования большинством определяются ближайшее похожее видео из базы, а также конкретный сегмент видео.
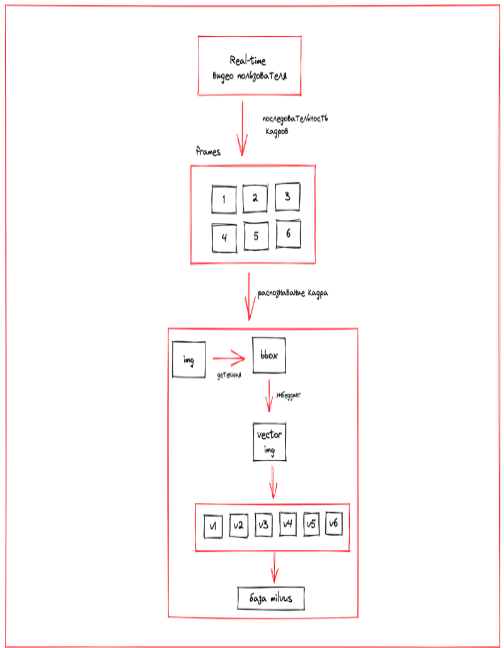
Как устроено распознавание видео
Автоматическое обновление базы видео
Когда мы хотим добавить новое видео в базу, нам необходимо обновлять базу Milvus. Для автоматизации этого процесса мы использовали еще один сервис — Datapipe. Это собственная разработка AGIMA AI, которую мы сделали для автоматизации подготовки данных и обучения ML-моделей и уже успешно использовали в двух проектах — оптическое распознавание символов для кэшбэк-платформы и модель машинного обучения для распознавания деталек лего в приложении Brickit (оно подсказывает, как собрать новые штуки из старых деталей).

Таким образом можно идентифицировать даже многосложные или иностранные названия объектов и привести их в единый формат, который требует Ozon
В системе Ozon все категории, свойства товаров и их значения пронумерованы. У продавца цвет товара может называться «зеленый» — для маркетплейса же это будет конкретный ID. Поэтому, чтобы понять суть товара и разложить его по полочкам, нам необходимо преобразовать информацию о нём в численный вектор.
«Сервис отслеживает изменения в облачной базе данных. Если в базе появляется новое видео — название и ссылка на файл, то сервис автоматически скачивает его, кадрирует, присваивает числовые векторы и загружает векторы в Milvus. После этого пользователь сможет найти это видео с помощью приложения».
ML-Engineer AGIMA AI
Анна Закутняя

После того, как нужный сегмент видео найден в базе Milvus, мы берем всю информацию об этом сегменте — описание фильма и товары — из таблиц, которые находятся в облачном сервисе. Этот сервис позволяет создавать таблицы, а затем искать в них информацию через API.
В итоге получается такая схема:
Как создаются списки товаров
Приложение определяет сегмент фильма.
Выдает пользователю:
- информацию о фильме;
- список товаров, которые были в сегменте.
Списки товаров создают и пополняют правообладатели — они сами прописывают описания и добавляют фотографии.
Команда
Андрей Татаринов
сооснователь AGIMA AI
Анна Закутняя
ML-инженер
Александр Козлов
ML-тимлид
Команда Amiga за короткие сроки сделала большую работу. Хочется отметить, что Amiga и AGIMA AI в синергии заточены под быстрый запуск MVP-версий. Заказчик получил полностью работающее мобильное приложение, в планах развивать его и дальше.
CEO Amiga
Дмитрий Тарасов
Технологии
YOLOv5
Детектор
MobileNet
Эмбедер - обученный на картинах с использованием слоя ArcFace
Milvus
База векторов
Grist
Таблицы c информацией по видео и товарам
Datapipe
ML-сервис для обновления базы Milvus
Flutter
Фреймворк для мобильного приложения
Фильм и товары распознаются за 2,4 секунды в режиме real-time.
Видео пользователя кадрируется со скоростью 1 кадр в 200 мс в режиме real-time.
Построили ML-модель, которая умеет распознавать 150 фильмов и товары в кадре. Базу фильмов можно автоматически пополнять.
Результаты
Точность распознавания видео — 96%.
